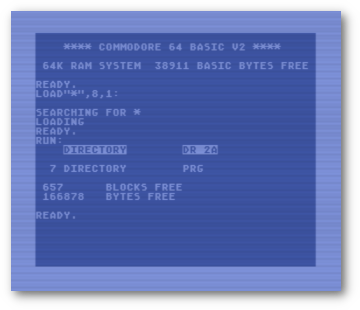
It’s one of those things that I couldn’t figure out as a kid that drove me crazy. I wanted to be able to get a disk directory from my 1541 disk drive while running a BASIC program and load the filenames into an array so I can list them on the screen and make them selectable. I even bought a book all about the 1541. It wouldn’t show me an easy way to get at the directory and I was never able to figure it out back in the 80s.
Fast forward to 2020 and I find myself wanting to load a disk directory into memory while running BASIC so I can select a file to load. Quite a bit older, I was determined to find the way. Curiously, I still didn’t find the answer right away on the internet.
The 1541 User’s Manual does have a program that supposedly allows you to read a disk directory in BASIC, but I couldn’t get it to work for me. It did lead me down the path I took to get what I needed though.
So this is my solution for reading a directory on the 1541 in BASIC. This allows me to get a list of files loaded into an array so I can select them within my program to load them. The programs is heavily documented and written in a very linear way to highlight how it is done. The program can be optimized quite a bit, but that wasn’t my purpose here.
So here we go:
Disk Image
Full program listing
100 DIMFI$(40),T%(40),BL%(40),T$(4)
110 FORN=0TO4:READT$(N):NEXT
120 BF=664:REM ** BLOCKS FREE ********
130 OPEN15,8,15,"I0:":CLOSE15:REM INITIALIZE DISK
140 OPEN2,8,2,"$"
First, I’ve set up some arrays to store the directory data. I’m assuming the directory won’t have more than 40 entries, but you can always increase that number. FI$() is the filename, T%() is the type of file, BL% is the number of blocks, and T$() is the list of filetypes (DEL, SEQ, PRG, USR, and REL). Line 110 loads the names of the filestypes into the T$() array.
This is very important. You need to initialize the disk before you read the directory. This is done on line 130. If you don’t do this, you will probably get garbage when trying to read the directory, especially if you change disks. This allows the 1541 to know that you have put a new disk in the disk drive.
Line 140 opens the directory file. Normally, ‘$’ is loaded using the LOAD”$”,8 command in direct mode. This will load the disk directory into memory, destroying any program you may have been working on. Until recently, I didn’t know ‘$’ could also be loaded as a sequential file. The things is, when you load ‘$’ this way, there is a lot of raw data that you don’t need but have to get through anyway because it is a sequential file.
The 1541 basically dumps all the contents of the sectors where the directory is stored on the disk. It starts with track 18, sector 0. Here is a chart of the first 143 bytes of 18.0. The first two bytes are not transmitted as the 1541 uses them internally to point to where the file listing is stored. Byte 2 has the ascii character ‘A’ indicating the drive is in 4040 format and byte 3 is null.

Bytes 4 to 143 are the bitmap of the BAM (Block Availability Map) which the 1541 uses to manage the disk space. This information is not needed for our directory listing so we need to get past it. Simply use a GET# command in a loop and don’t do anything with the data.
160 REM ** NOT NEEDED FOR DIRECTORY **
170 FORN=2TO143:GET#2,A$:NEXTNOnce we get through the BAM, we get to bytes 144 through 161. These bytes store the name of the disk. Any bytes not used by the disk name are padded with shifted spaces (petscii 160). A quick FOR/NEXT loop to pull the data and then check to make sure the data is not a padded space will get us the disk name in a variable (in this case D$). We then print it to the screen in reversed characters (CHR$(18)).
190 REM ** GET THE DISK NAME *********
200 FORN=144TO161
210 GET#2,A$:IFA$<>CHR$(160)THEND$=D$+A$
220 NEXTN
230 PRINTSPC(4);CHR$(18);D$;SPC(17-LEN(D$));After the disk name, 2 bytes are used for the disk ID. After that, there a padding byte followed by 2 bytes for the disk operating system (which is 2A). Here’s how I grab them in the program. I also print them out at the same time.
250 REM ** GET THE DISK ID ***********
260 GET#2,A$:PRINTA$;
270 GET#2,B$:PRINTB$;" ";
280 ID$=A$+B$
290 GET#2,A$
300 :
310 REM ** GET THE DOS VERSION *******
320 GET#2,A$:PRINTA$;
330 GET#2,B$:PRINTB$
340 OS$=A$+B$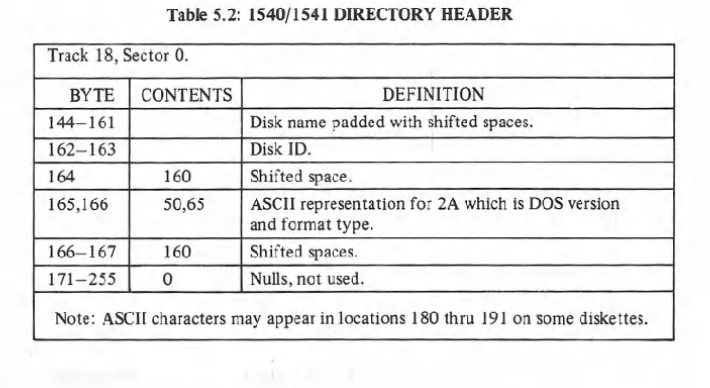
As you can see in the chart above, this is all the information that we need from track 18, sector 0. The rest of the data in 18.0 is unused. Again, we still need to read it all, so another FOR/NEXT loops reads it and discards it.
360 REM ** LOTS OF UNUSED DATA *******
370 FORN=167TO255:GET#2,A$:NEXTNThe program has now read the entire content of track 18, sector 0. Now the next dump of data will be from track 18, sector 1 which holds the file names of the files on the disk. According to the chart below, each sector contains 8 file name entries.
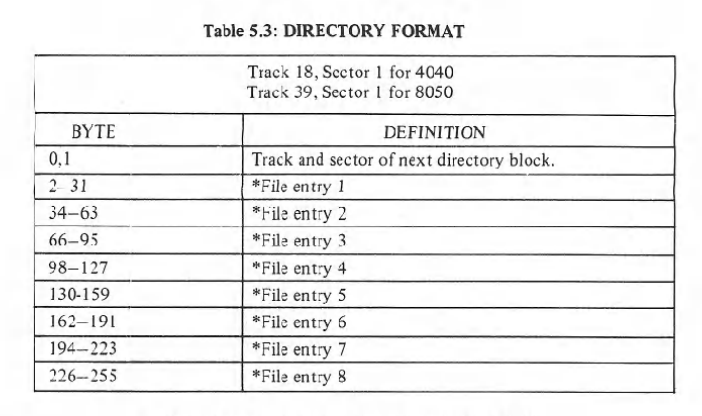
Like sector 0, the first two bytes of the sector are not transmitted. So we don’t need to get them. Each file entry contains 29 bytes and there are 2 bytes padding between each entry. Here is the structure of those 29 bytes in the chart below.
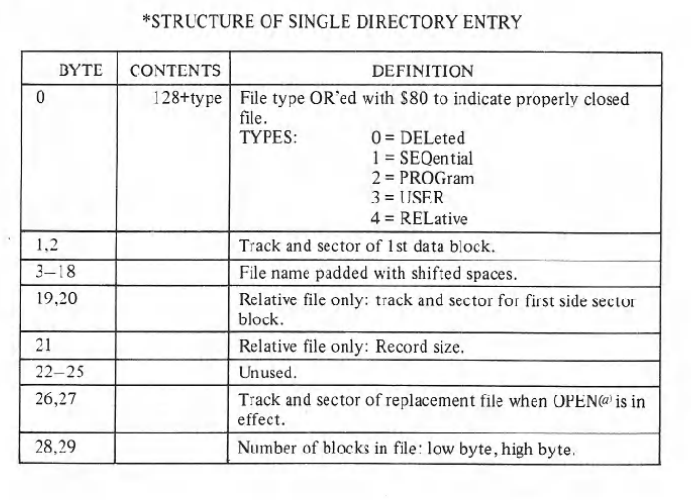
The first thing to grab from the file entry is the type of file. As the chart above indicates, a good file is going to have a number of 128 or higher (128 being deleted files that you can see in directory listings.)
400 REM ** GET THE FILE TYPE *********
410 REM ** OTO4 PLUS 128 FOR GOOD FILE
430 GET#2,A$:IFA$=""THENT=0:GOTO470
440 T=ASC(A$)The next 2 bytes are the track and sector location of the actual file. We don’t need them for a directory listing, so we just GET# them and move on.
460 REM ** DON'T NEED THESE 2 BYTES **
470 GET#2,A$,A$We’ve gotten to the file name of the entry. There are 16 bytes used for the name. Just like the disk name, any unused bytes will be padded with shifted spaces (petscii 160). A loop like the one used for the disk name is used to capture the file name.
490 REM ** NOW GET FILE NAME *********
500 F$=""
510 FORN=3TO18
520 GET#2,A$:IFA$<>CHR$(160)THENF$=F$+A$
530 NEXTNAccording the chart above, bytes 19 through 27 are used for different things needed by the 1541 to process relative files as well as the new location of the file when you do an @0: save. These are not needed for the directory listing, so we’ll bypass them.
550 REM ** DON'T NEED THESE BYTES ****
560 FORN=19TO27:GET#2,A$:NEXTNFinally, byte 28 and 29 are a 16 bit integer indicating the number of blocks the programs takes up. They are stored in low byte, high byte order. Two GET# statements and a little bit of math gets us the blocks used.
580 REM ** GET LO/HI BLOCKS USED *****
590 GET#2,A$:IFA$=""THENL=0:GOTO610
600 L=ASC(A$)
610 GET#2,A$:IFA$=""THENH=0:GOTO630
620 H=ASC(A$)
630 BL=L+(H*256)Finally, we’re ready to print the full line of file name, type, and blocks used. We want to check to make sure the entry isn’t a deleted file first. The way the directory works is that when a file is deleted, it just gets marked with a file type #0. This tells the 1541 that there is no valid file there. It does not resort the file name entries on the disk, it just leaves a hole to be filled with a new file when you write one. That is why when you delete files and write new ones, the new files names are inserted into the middle of the directory listing. The BASIC program does a quick check of the file type and skips it if it is zero.
650 REM ** IF DEL FILE SKIP PRINT ****
660 IFT=0THEN770The program then calculates how much space is left on the disk by simply subtracting the number of blocks from the file entry from the variable BF (BlocksFree) that was assigned 664 earlier in the program.
The program then saves all the file entry information into their corresponding arrays to be used by BASIC later and prints them out on the screen. It also checks to make sure the file entry type is greater than 127 indicating that it is a valid file that has been closed correctly. If not, it still prints the entry but adds an asterisk next to the program type to indicate it is a bad file.
670 BF=BF-BL
680 BL%(FI)=BL:T%(FI)=T:FI$(FI)=F$:FI=FI+1
690 IFBL<10THENPRINT" ";
700 PRINTBL;
710 PRINTF$;SPC(17-LEN(F$));
720 IFT>127THENPRINTT$(T-128):GOTO740
730 PRINT"*"T$(T)Next, we need to check to see if we’ve read all 8 file entries in the current sector. The ‘$’ will send an entire sector’s worth of data down the line even if there is only one file entry in it. Only after a sector has been completely read with the directory listing be completed. You should also notice that while we’re pulling file entries from the same sector, there is a two byte padding that needs to be read. Line 770 does this as well. If file entries jump between sectors, then there is no padding between then and the GET#2,A$,A$ is skipped.
750 REM ** FILENAMES SAVED IN BLOCKS *
760 REM ** OF 8. PADDING CHANGES *****
770 IFFE<7THENFE=FE+1:GET#2,A$,A$:GOTO790
780 FE=0Finally, we check the status of the file to see if we’ve read the entire directory. If we have, go to close the ‘$’ file, print some final data and end. If not, we go back up to the next file entry and read its contents.
790 IFSTTHEN810
800 GOTO430
810 CLOSE2
820 PRINT,,:PRINT :PRINTBF,"BLOCKS FREE"
830 PRINTBF*254,"BYTES FREE":REM ONLY 254 BYTE/BLOCK
840 END
850 DATA "DEL","SEQ","PRG","USR","REL"So that’s it. The steps I used to load a disk directory from a 1541 disk drive into my computer using BASIC. Basic is a little slow reading it, but the idea is to read it once, store the filenames in an array to use and only run a directory when you change disks or alter the directory on the disk you’re working on. Also, these steps can be replicated in machine language if that’s the direction you want to go. I haven’t done that yet, but I’m sure I will find a need down the road.